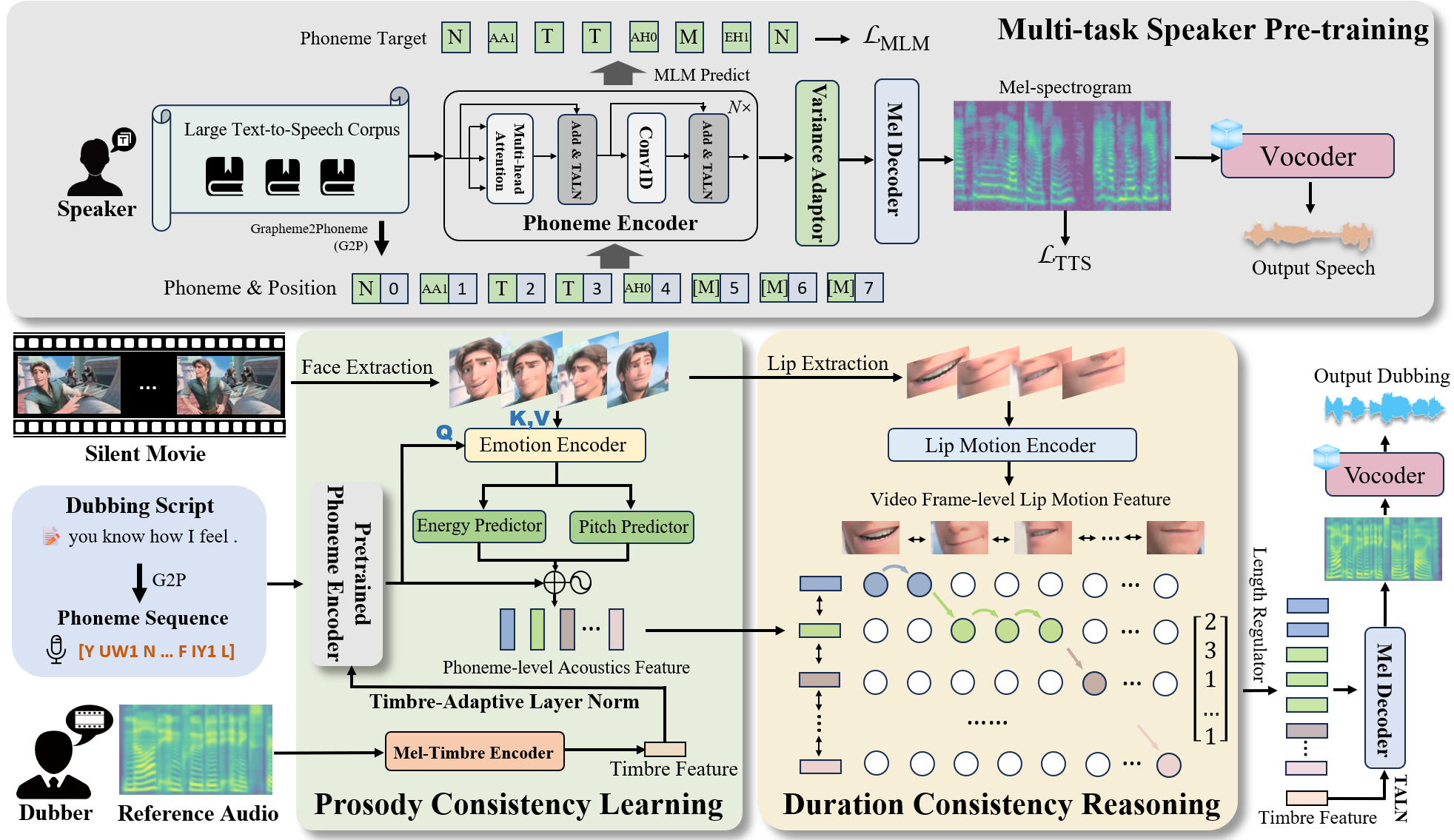
Movie Dubbing aims to convert scripts into speeches that align with the given movie clip in both temporal and emotional aspects while preserving the vocal timbre of one brief reference audio. The wide variations in emotion, pace, and environment that dubbed speech must exhibit to achieve real alignment make dubbing a complex task. Considering the limited scale of the movie dubbing datasets (due to copyright) and the interference from background noise, directly learning from movie dubbing datasets limits the pronunciation quality of learned models. To address this problem, we propose a two-stage dubbing method that allows the model to first learn pronunciation knowledge before practicing it in movie dubbing. In the first stage, we introduce a multi-task approach to pre-train a phoneme encoder on a large-scale text-speech corpus for learning clear and natural phoneme pronunciations. For the second stage, we devise a prosody consistency learning module to bridge the emotional expression with the phoneme-level dubbing prosody attributes (pitch and energy). Finally, we design a duration consistency reasoning module to align the dubbing duration with the lip movement. Extensive experiments demonstrate that our method outperforms several state-of-the-art methods on two primary benchmarks. The source code and model checkpoints will be released to the public. The demos are available at this page.
V2C-Animation sample on Dub 1.0
Sample #1
Script: Every night it sneaks in my yard and gobbles my poor azaleas.
StyleSpeech
Zeroshot-TTS
V2C-Net
HPMDubbing
Ours
GT
Sample #2
Script: This is very serious.
StyleSpeech
Zeroshot-TTS
V2C-Net
HPMDubbing
Ours
GT
Sample #3
Script: Everyone wants the hot, new thing.
StyleSpeech
Zeroshot-TTS
V2C-Net
HPMDubbing
Ours
GT
GRID sample on Dub 1.0
Script: bin blue at s three again
StyleSpeech
Zeroshot-TTS
V2C-Net
HPMDubbing
Ours
GT
V2C-Animation sample on Dub 2.0
Sample #1
Script: Sentient food? That’s impossible.
Reference Audio:
StyleSpeech
Zeroshot-TTS
V2C-Net
HPMDubbing
Ours
GT
Sample #2
Script: Here’s what I heard: “Blah, blah, blah.”
Reference Audio:
StyleSpeech
Zeroshot-TTS
V2C-Net
HPMDubbing
Ours
GT
Sample #3
Script: Well, I just saved our lives.
StyleSpeech
Zeroshot-TTS
V2C-Net
HPMDubbing
Ours
GT
Zero-shot sample test
Sample #1
Script: How do we know that this isn’t some trick?